Visual Target Navigation using 3D Scene Priors

Abstract: Recently, visual target navigation is important and non-trivial for autonomous robots because it closely relates to the ability of cognitive reasoning. Classical methods and learning based methods are fundamental components of robot navigation which have been studied for a long time. However, the representation of the scene memory and priors, and the generalization of method in unseen scene are the core challenges due to the complexity and indeterminacy of the indoor scene. Here, we proposed a framework for visual target navigation that efficiently fuses the SLAM and deep reinforcement learning method with explicit 3D scene priors. In the proposed method, we adopt SLAM to build a semantic map as scene memory and learn navigation policy based on the real-time map and explicit scene priors to make the optimal decision. Afterward, the 3D scene priors are generated from Visual Genome dataset and incorporated with the framework using R-GCN. The explicit scene memory and priors can provide more intuitional features for visual target navigation tasks than the implicit representation learning from networks. Experiment results demonstrate that the proposed framework significantly outperforms existing methods in the target navigation task in the unseen scene. We also compared our method with the human subjective decision in visual target navigation.
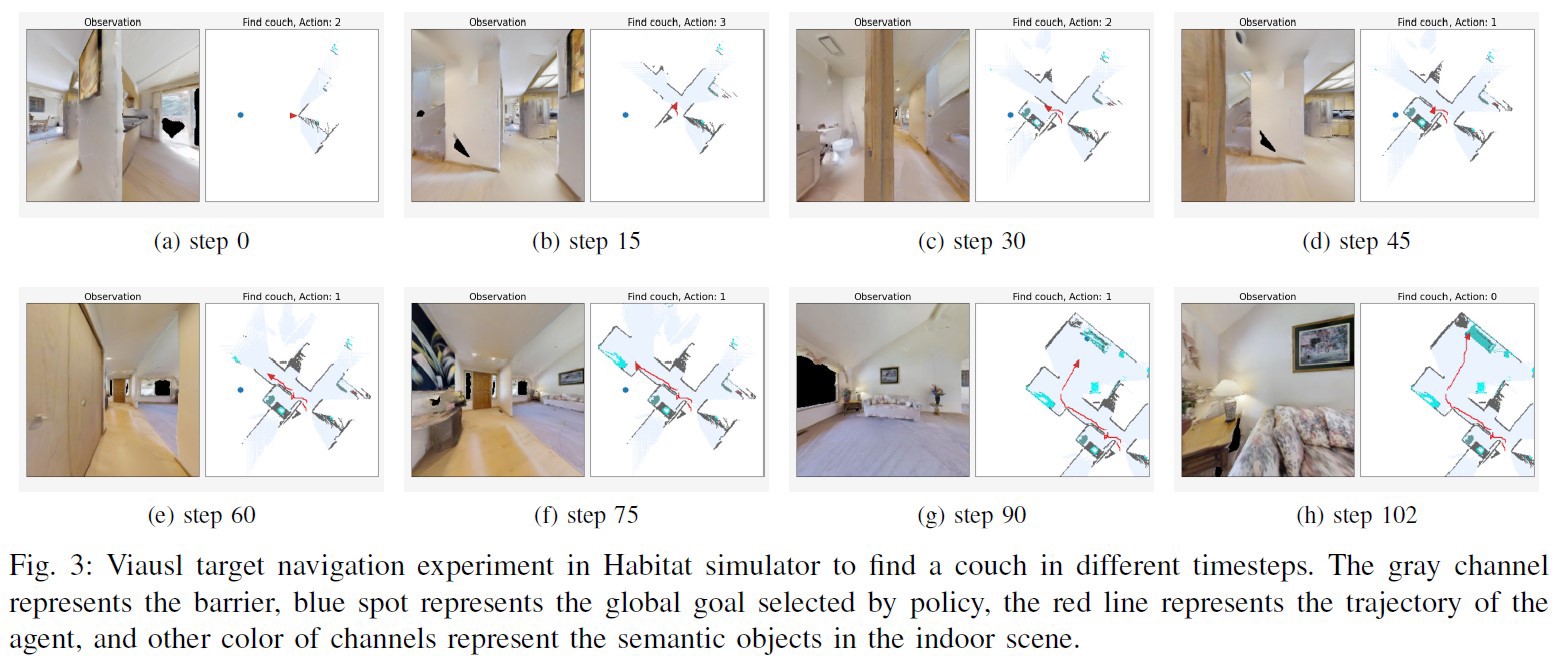
Now I have build my own Objectnav datasets using Gibson. The detail of the Objectnav datasets are shown in “https://github.com/ybgdgh/Habitat-Objectnav-Task-Datadet-Geneartion". The total code of target navigation can be found in “https://github.com/ybgdgh/Visual-Target-Navigation".



Bangguo Yu
PhD Student
My research interests include mobile robotics, 3D scene graph and deep reinforencement learning in target-driven navigation.