 3D scene graph
3D scene graphAbstract
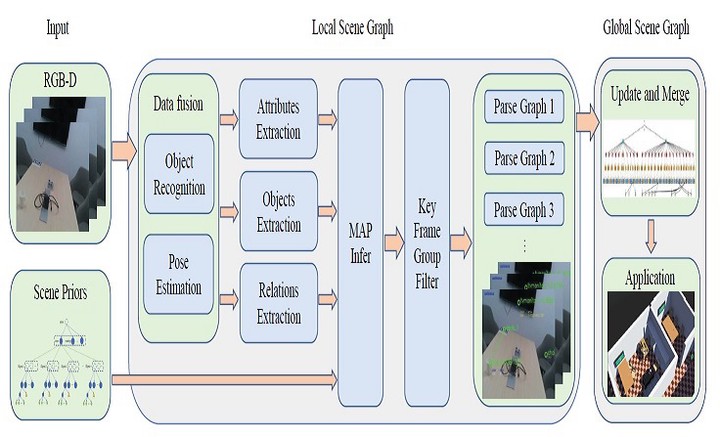
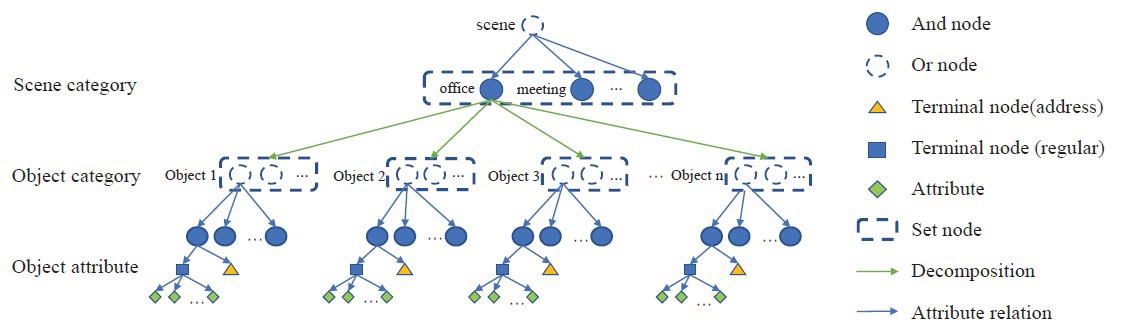
Abstract—For high-level human-robot interaction tasks, 3D scene understanding is important and non-trivial for autonomous robots. However, parsing and utilizing effective environment information of the 3D scene is not trivial due to the complexity of the 3D environment and the limited ability for reasoning about our visual world. Although there have been great efforts on semantic detection and scene analysis, the existing solutions for parsing and representation of the 3D scene still fail to preserve accurate semantic information and equip sufficient applicability. This study proposes a bottomup construction framework for structured 3D scene graph generation, which efficiently describes the objects, relations and attributes of the 3D indoor environment with structured representation. In the proposed method, we adopt visual perception to capture the semantic information and inference from scene priors to calculate the optimal parse graph. Afterwards, an improved probabilistic grammar model is used to represent the scene priors. Experiment results demonstrate that the proposed framework significantly outperforms existing methods in terms of accuracy, and a demonstration is provided to verify the applicability in applying to high-level human-robot interaction tasks.
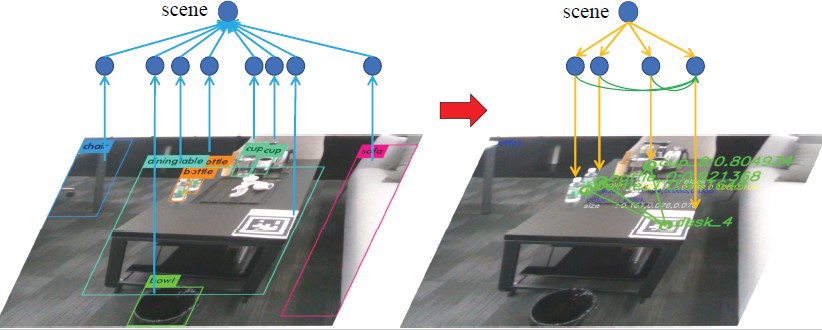


We use laser to provide the location information and use scene graph to achieve the target-driven navigation.
