A Bottom-up Framework for Construction of Structured Semantic 3D Scene Graph
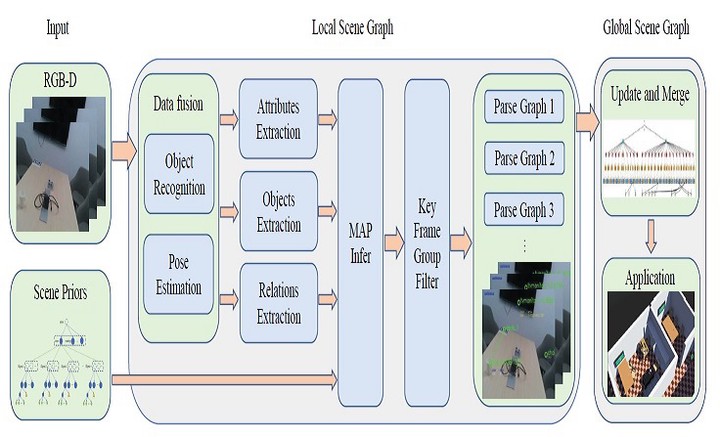 3D scene graph
3D scene graphType
Publication
In IEEE/RSJ International Conference on Intelligent Robots and Systems
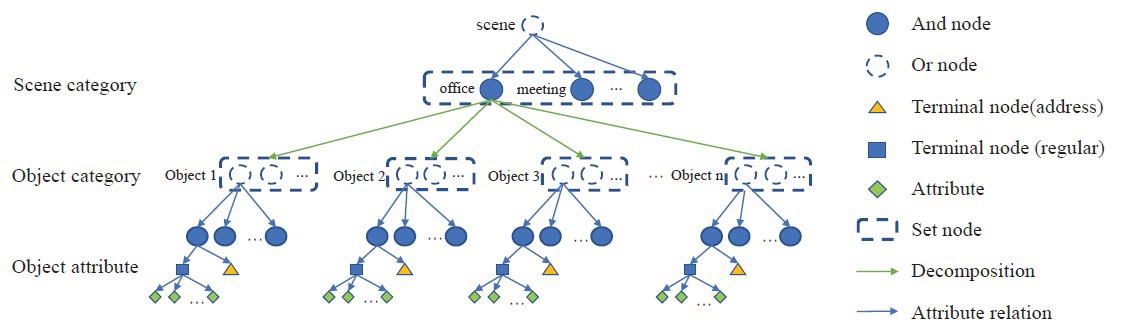
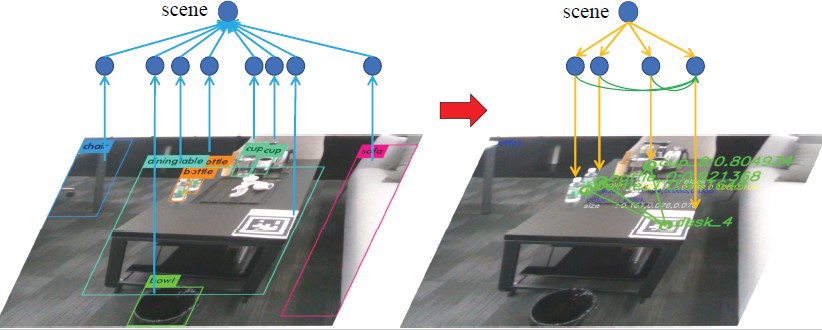


We use laser to provide the location information and use scene graph to achieve the target-driven navigation.
